Data Engineering
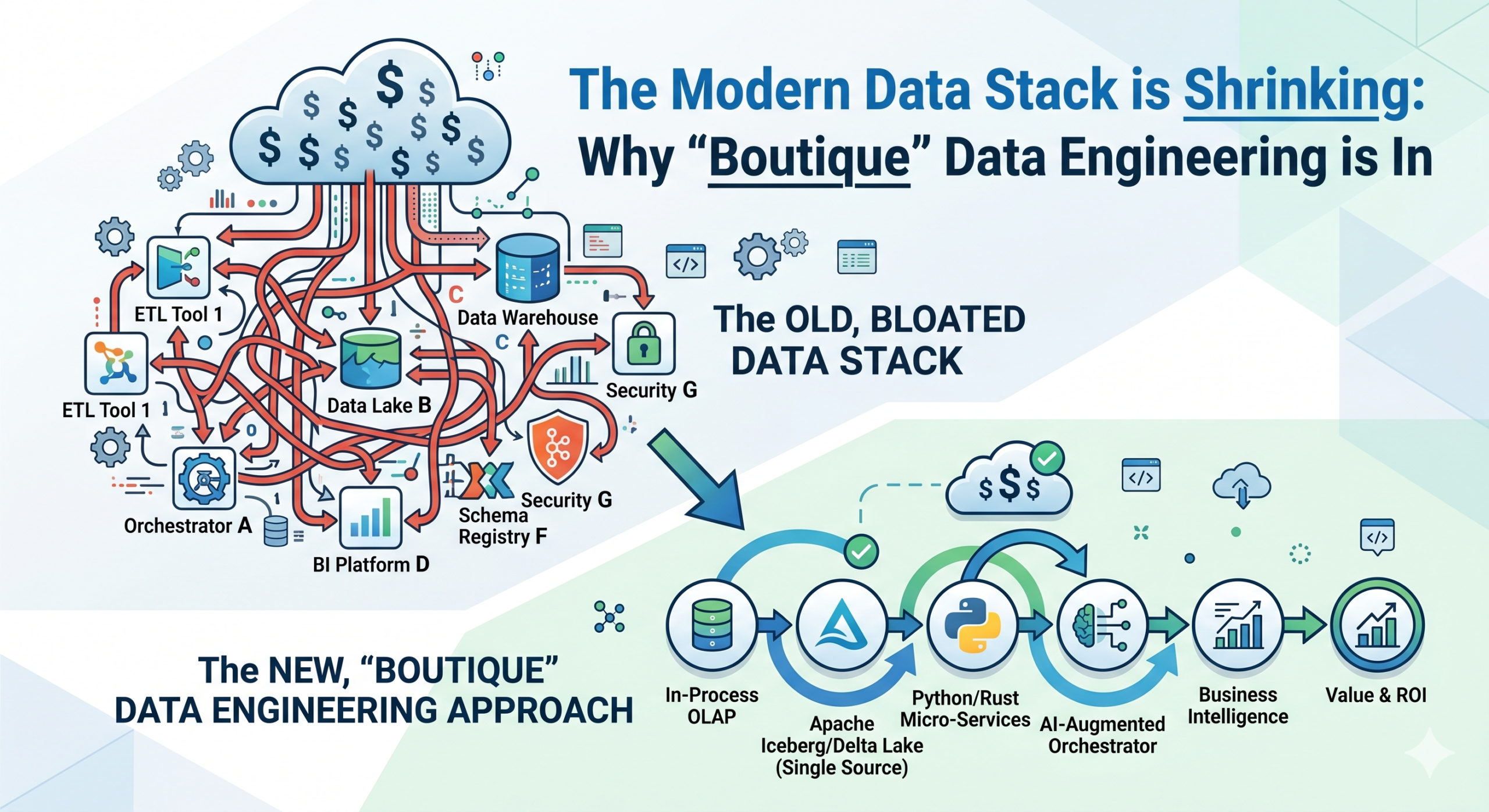
The Modern Data Stack is Shrinking: Why “Boutique” Data Engineering is In
The Evolution of the Pipeline
For the last few years, the mantra in Data Engineering was “more is better.” More tools, more layers, more microservices. We built sprawling architectures with separate tools for ingestion, transformation, orchestration, and observability.
But in 2026, the tide has turned. We are entering the era of the Boutique Data Stack—where efficiency, cost-optimization, and “local-first” development are replacing the bloated cloud bills of yesteryear.
Key Trends Shifting the Landscape
- The Rise of DuckDB and In-Process OLAP: We’re moving away from sending every kilobyte of data to a massive cloud warehouse. High-performance, in-process databases allow engineers to run complex analytical queries locally or at the edge, saving thousands in egress fees.
- Zero-Copy Integration: The “Copy-Paste” era of data movement is dying. With technologies like Apache Iceberg and Delta Lake, we are finally seeing a world where different tools can query the same data files without moving them.
- AI-Augmented Orchestration: We’ve moved past static DAGs (Directed Acyclic Graphs). Modern orchestrators now use LLMs to self-heal pipelines, automatically adjusting schemas when a source API changes unexpectedly.